
Similarity measures
Once data are collected, we may be interested in the similarity
(or absence thereof) between different samples, quadrats, or
communities
Numerous similarity indices have been proposed to measure the
degree to which species composition of quadrats is alike
(conversely, dissimilarity coefficients assess the degree to
which quadrats differ in composition)
Jaccard coefficient
Simplest index, developed to compare regional floras (e.g.,
Jaccard 1912, The distribution of the flora of the alpine zone,
New Phytologist 11:37-50); widely used to assess similarity of
quadrats
- Uses presence/absence data (i.e., ignores info about abundance)
- SJ = a/(a + b + c), where
- SJ = Jaccard similarity coefficient,
- a = number of species common to (shared by) quadrats,
- b = number of species unique to the first quadrat, and
- c = number of species unique to the second quadrat
- e.g., given the following data:
| quadrat | sp 1 | sp 2 | sp 3 | sp 4 | sp 5 | sp 6 |
| i | 3 | 4 | 2 | 1 | 0 | 0 |
| j | 3 | 3 | 0 | 5 | 2 | 1 |
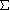 kyki = 3 + 4 + 2 + 1 + 0 + 0 = 10
kyki = 3 + 4 + 2 + 1 + 0 + 0 = 10
-
kykj = 3 + 3 + 0 + 5 + 2 + 1 = 14
-
kyki2 = 32 +
42 + 22 + 12 + 02 +
02 = 30
-
kykj2 = 32 +
32 + 02 + 52 + 22 +
12 = 48
-
kykiykj = 3(3) + 4(3) + 2(0) +
1(5) + 0(2) + 0(1) = 27
SJ is frequently multiplied by 100%, and may be represented in
terms of dissimilarity (i.e., DJ = 1.0 -
SJ)
Sørensen coefficient (syn. coefficient of community, CC)
A very simple index, similar to Jaccard's index
Give greater "weight" to species common to the quadrats than to
those found in only one quadrat
- Uses presence/absence data:
- SS = 2a/(2a + b + c), where
- Sørensen similarity coefficient,
- a = number of species common to both quadrats,
- b = number of species unique to the first quadrat, and
- c = number of species unique to the second quadrat
SS usually is multiplied by 100% (i.e., SS = 67%),
and may be represented in terms of dissimilarity (i.e., DS =
1.0 - SS)
Similarity ratio
Similarity between quadrats i and j is
SRij =
kykiykj /
(
kyki2 +
kykj2 -
kykiykj), where
yki = abundance of kth species in quadrat
i
For presence-absence data, SR reduces to the Jaccard index
Percentage similarity (syn. Czekanowski coefficient)
Percentage similarity between quadrats i and j is
PSij = 200 k
min(yki, ykj) / (kyki
+ kykj),
where
min(yki, ykj) = minimum value of yki and
ykj
For presence-absence data, PS reduces to the Sørensen
index
Euclidean distance (syn. coefficient of squared Euclidean
distance)
Generalized formula for Euclidean distance is
EDij = 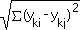 , where
, where
EDij = Euclidean distance between quadrats i and j, and
yki = abundance of kth species in quadrat
i
ykj = abundance of kth species in quadrat
j
Euclidean distance is routinely used as a measure of similarity
in cluster analyis algorithms
Direct gradient analysis
Graphics
- Multivariate analyses are required for community data because
we're interested in the response of many species, simultaneously
- Multivariate analyses are used to summarize redundancy,
reduce noise, elucidate relationships, and identify outliers
- Multivariate analyses can relate communities to other kinds
of data (e.g., environmental, historical data)
- Results from multivariate analyses are designed to improve
our understanding of communities, esp. community structure
- Direct gradient analysis
- Used to display distribution of organisms along gradients of
important environmental factors
- Devised by Ramensky (1930) and Gause (1930), but used
extensively in ecological research after about 1950
(Whittaker)
- An example:
- Dix and Smeins (1967) took 100 community samples to represent the
range of vegetation present in Nelson County, North Dakota
- Homogeneous stands of 0.1 ha were sampled by recording
frequency in 30, 0.5 × 0.5 m quadrats
- Numerous environmental variables were recorded for each
stand
- Defined indicator species of a drainage class as a species
w/ frequency at least 10% greater in that class than in any
other class
- Defined indicator value as drainage class of the indicator
species {drainage classes vary from 1 (good) to 6 (poor)}
- Goal: summarize frequency of all species --> single
number for each stand
- Stand Index Number = {(rel. freq. ×
indicator value)/{(rel. freq. of
indiv. sp)} × 100
- e.g., Stand 17 (sample data) {RF=rel. freq.,
IV=indicator value}:
| Spp. | RF | IV | RF x
IV | |
| Stco | 20 | 1 | 20 | |
| Stvi | 10 | - | -- | (not an indicator for any drainage class) |
| Acmi | 15 | 2 | 30 | |
| Lica | 5 | 3 | 15 | |
| Other | 50 | - | -- | |
| 40* | | 65 | |
- *sum of RF for spp. w/ IV (20+15+5)
- Stand Index 17 = (65/40) × 100 = 162
- For all stands, stand index varied from 100 to 600
- Divided this 500-unit gradient into 10, 50-unit classes:
| Class | Stand w/in 50-uinit class | A |
B | C |
| 100-149 | 4 | | | |
| | 9 | | | |
| | 12 | | | |
| | | XA | XB | XC |
| 150-199 | | | | |
and so on ...
=========> Fig. 2 [Dix and Smeins
1967, p. 33]
- They could have plotted frequency over the entire 500-unit
gradient, but the graph would have been messy--10 drainage
classes "smooths" the graph, making interpretation easier
- The purpose of direct gradient analysis is to organize community
and environmental data to answer questions such as:
- Precisely which environmental factor in a complex of
factors
principally affects distribution of organisms and
communities?
- While direct gradient analysis can be used to identify
ecologically important environmental factors,
experimental manipulations are needed to more precisely
determine the importance of various environmental
factors
- How can environmental factors best be measured or estimated?
- Dix and Smeins derived an index for drainage based on
the plants themselves: this may be easier, more
accurate, and less expensive than other measures of
drainage or soil moisture
- What additional environmental gradients affect community
composition?
- Often difficult to evaluate because secondary gradients are
overshadowed by primary gradients
- What general principles emerge from direct gradient analysis
to characterize the combining of individual species into
communities?
More
graphics
- Characteristics of DGA:
- Data are plotted along environmental axes which are
generally accepted as given. Axes can be:
- direct
- indirect
- synthetic
- Species, communities, and community-level characteristics
can be plotted
- Several dimensions are possible
- Some form of data-smoothing is usually employed prior to
presentation
- common smoothing technique is weighted average for each
datum; e.g.,
- {current datumsmoothed = previous datum + 2
× current datum + next datum/4}
- resulting curve is less "noisy" than original data
- Whittaker offered the following conclusions about DGA:
- The general form for the distribution of a species
population along an environmental complex-gradient is the
bell-shaped curve
- The center (or mode) of a species population along a
complex-gradient is not at its physiological optimum
but is a center of maximum population success in
competition with other species populations
- The centers of species populations are scattered along
a complex-gradient in an apparently random manner
- One important qualification: in some cases, competing
species appear to be not randomly but regularly
distributed along environmental complex-gradients
- According to Whittaker, these considerations imply the
following:
- Species do not form well-defined groups of associates with
similar distributions, clearly separate from other such
defined groups, but are distributed according to the
principle of species individuality; each species is
distributed in its own manner, according to its own genetic,
physiological, and population response to environmental
factors that affect it, including effects of other species
- Along an environmental complex-gradient, species populations
(w/ their scattered centers and broadly overlapping
distributions) form a population continuum or compositional
gradient, suggesting that, in the absence of environmental
discontinuity or disturbance, communities intergrade or are
continuous w/ one another
- These conclusions led Whittaker to reject the "community-
unit" hypothesis
- Whittaker's conclusions were strongly influenced by his belief in
bell-shaped curves of species distributions
- The bell-shaped curve concept was challenged by Austin (1976,
Vegetatio 33:33-41) in a summary of previously published data:
| | linear | bell |
symmetric | skewed | very
skewed | bimodal | total |
| Curtis | 4 | 0 | 3 | 7 | 2 | 8 | 24 |
| Noy-Meir | 0 | 1 | 2 | 4 | 0 | 0 | 7 |
| Monk | 3 | 2 | 3 | 1 | 1 | 8 | 18 |
| Total | 7 | 3 | 8 | 12 | 3 | 16 | 49 |
| Percent of
Total | 14 | 6 | 16 | 24 | 6 | 33 | |
| | bell
(%) | skewed | shouldered | plateau | bimodal | total |
| Whittaker | | | | | | |
| Smokies | 8 (23%) | 6 | 10 | 2 | 9 | 35 |
| Siskiyous | 14 (27%) | 16 | 8 | 1 | 12 | 51 |
- Austin therefore concluded that the general form of the species
population is not normal, bell-shaped. And he was considering
data which had already been smoothed
- Werger (1983, Vegetatio 52:141-150) used a very conservative
yardstick for "normal" distribution (50% of variation accounted
for by curve)
- 31% of species normally distributed:
- 1 of 8 species (12%) on ridge tops
- 12 of 22 species (55%) midslope
- 5 of 32 species (16%) in swales
- The data collected and summarized by Austin and Werger indicate
that there is no a priori reason to assume bell-shaped normal
curves for distributions of species on gradients
- Conclusions about DGA:
- DGA is of unquestionable value and utility in ecology as a
means of
- data summarization and presentation, and
- hypothesis generation
- DGA is soundly based in classical plant ecology (e.g., Jack
Major's functional factorial approach to plant ecology--
vegetation = f(topography, organisms, time, soil, climate)
- The use of data-smoothing may be misleading
- There is a high degree of subjectivity inherent in this
method
- DGA (esp. w/ "synthetic" indices) is inherently circular
- Circularity results from subjective (pre-conceived)
sampling design--note that this was a criticism
launched by Whittaker (among others) against the
Clementsian approach of "seeing" communities and
sampling w/in them.
- The DGA-based conclusion of vegetation continuum
results from arbitrary, subjective sampling (just as
the discrete-community conclusion derives from sampling
w/in well-defined communities which appear to be
different.
- Both schools describe, but do not answer "why"? Both
groups base conclusions on descriptive data, w/o
testing hypotheses.
Previous
lectureNext
lecture